Building Workflows
The core principle of Orange is visual programming, which means each analytical step in contained within a widget. Widgets are placed on the canvas and connected into an analytical workflow, which is executed from left to right. Orange never passes data backwards.
Simple workflow
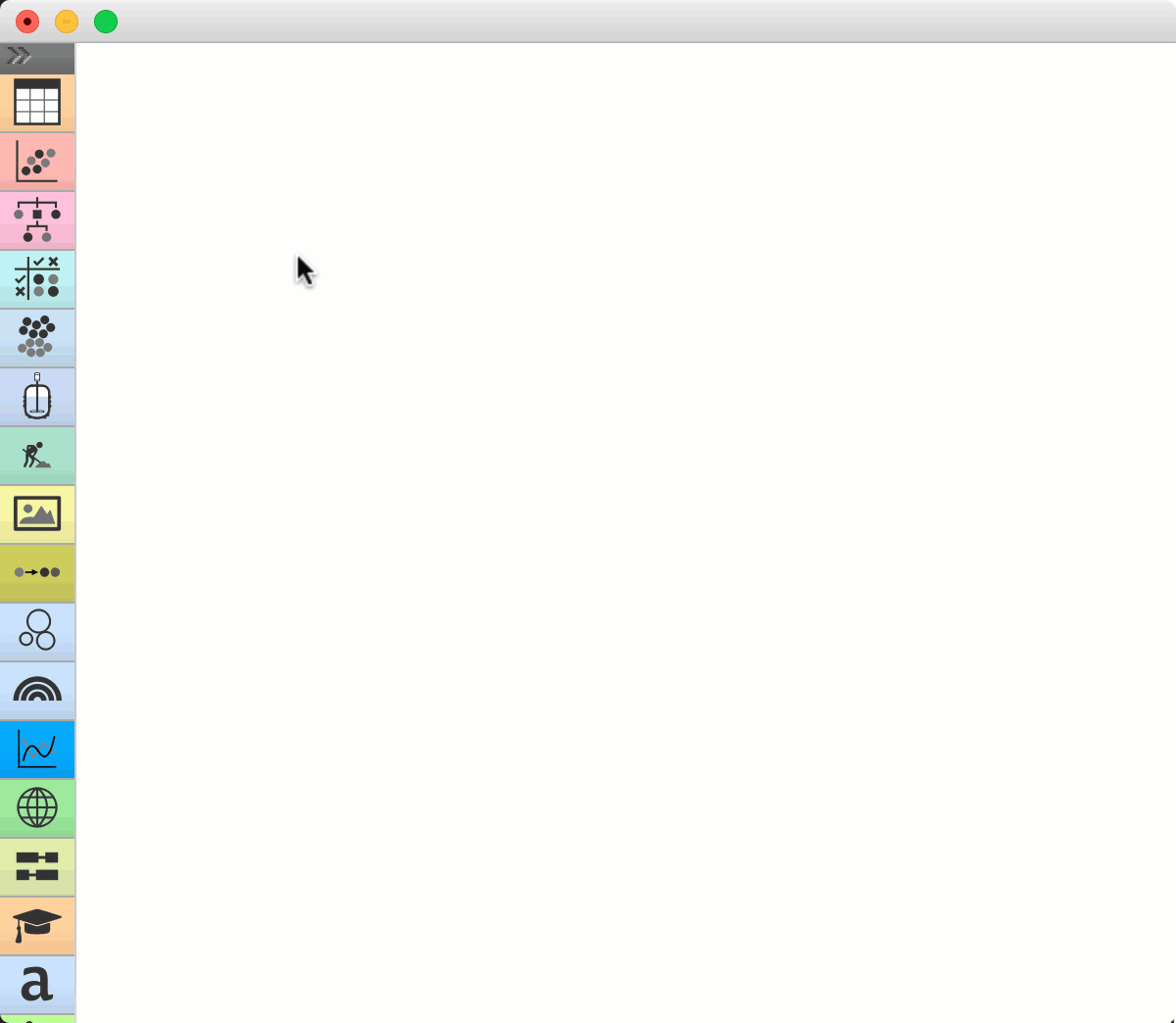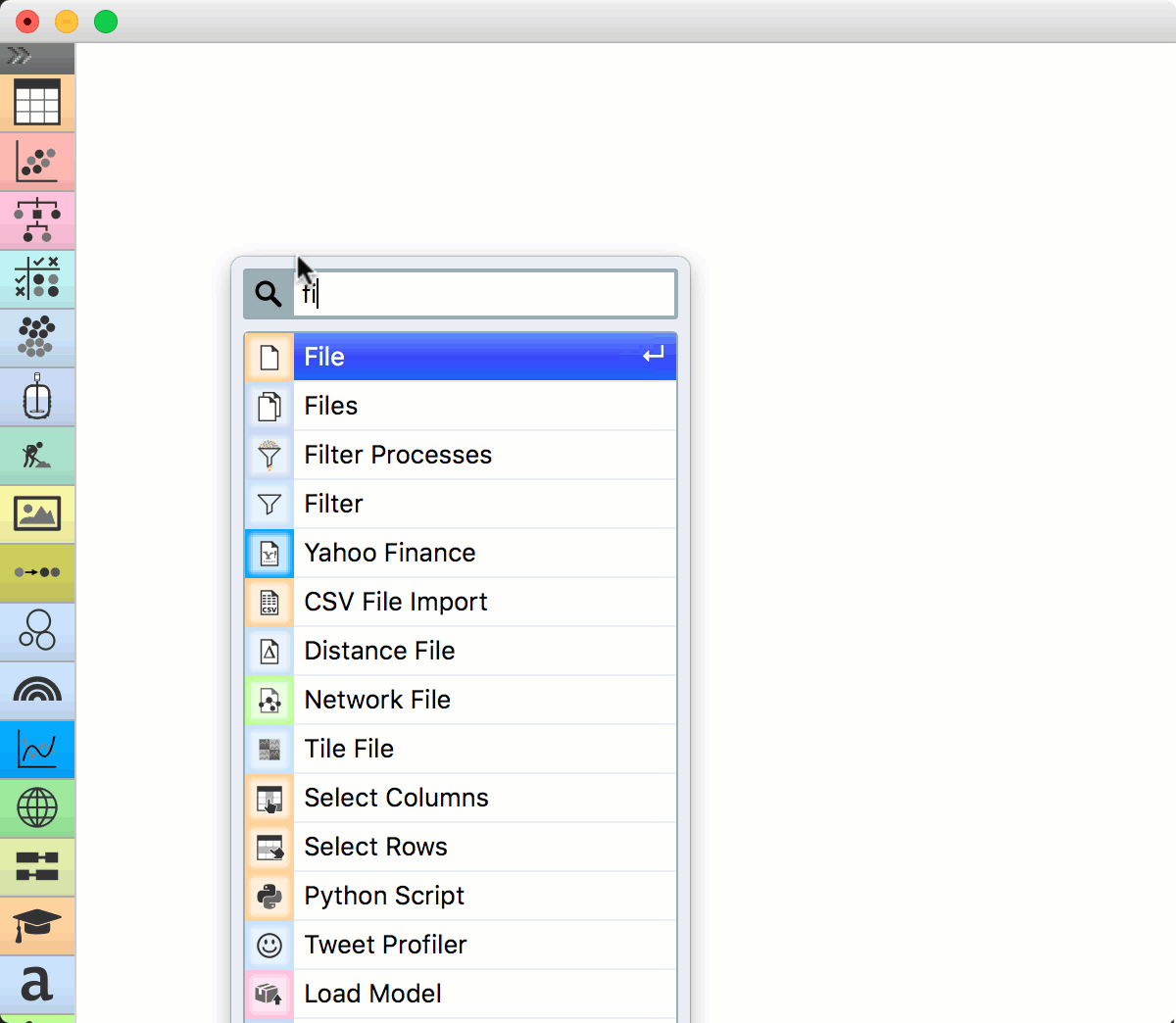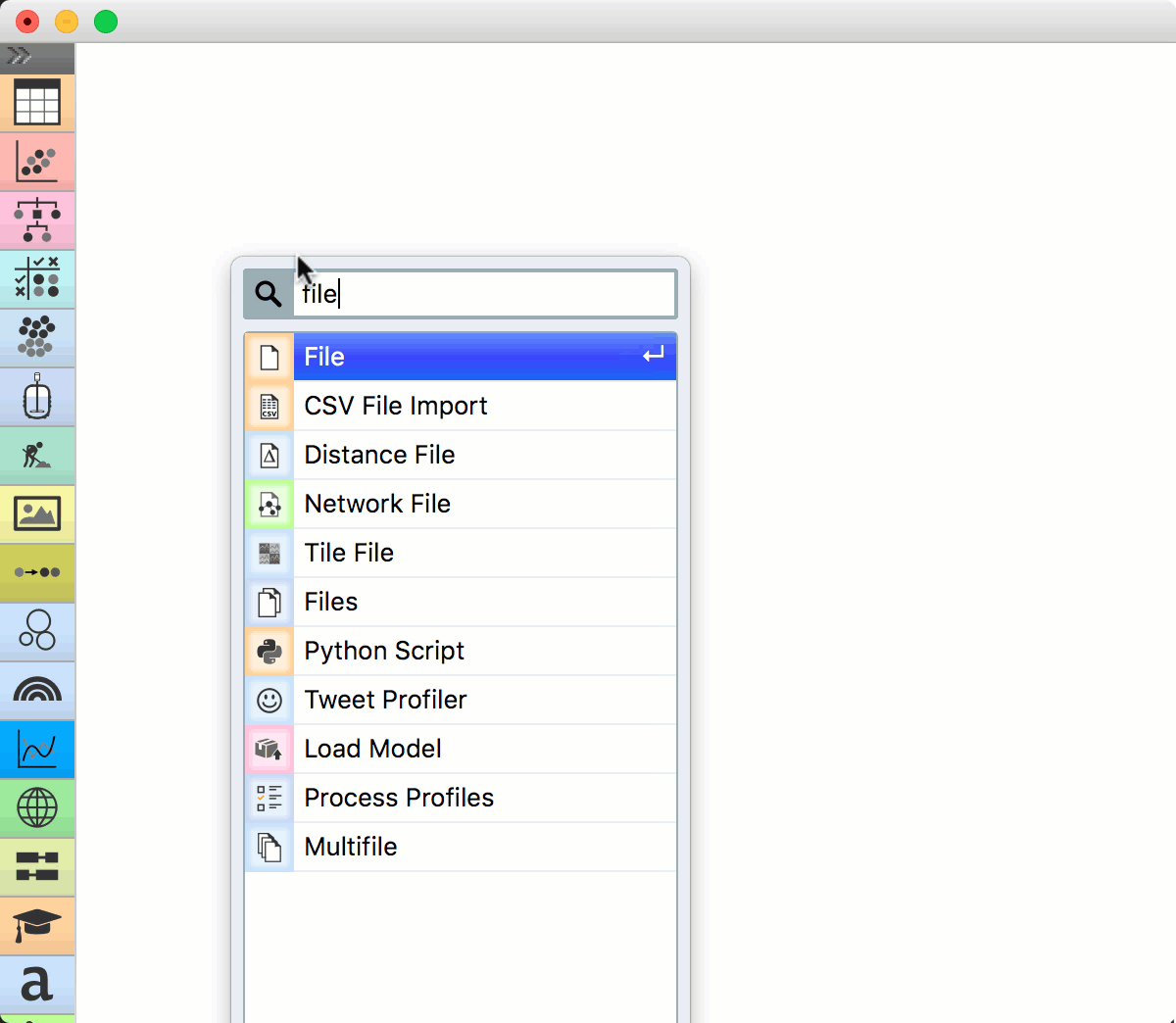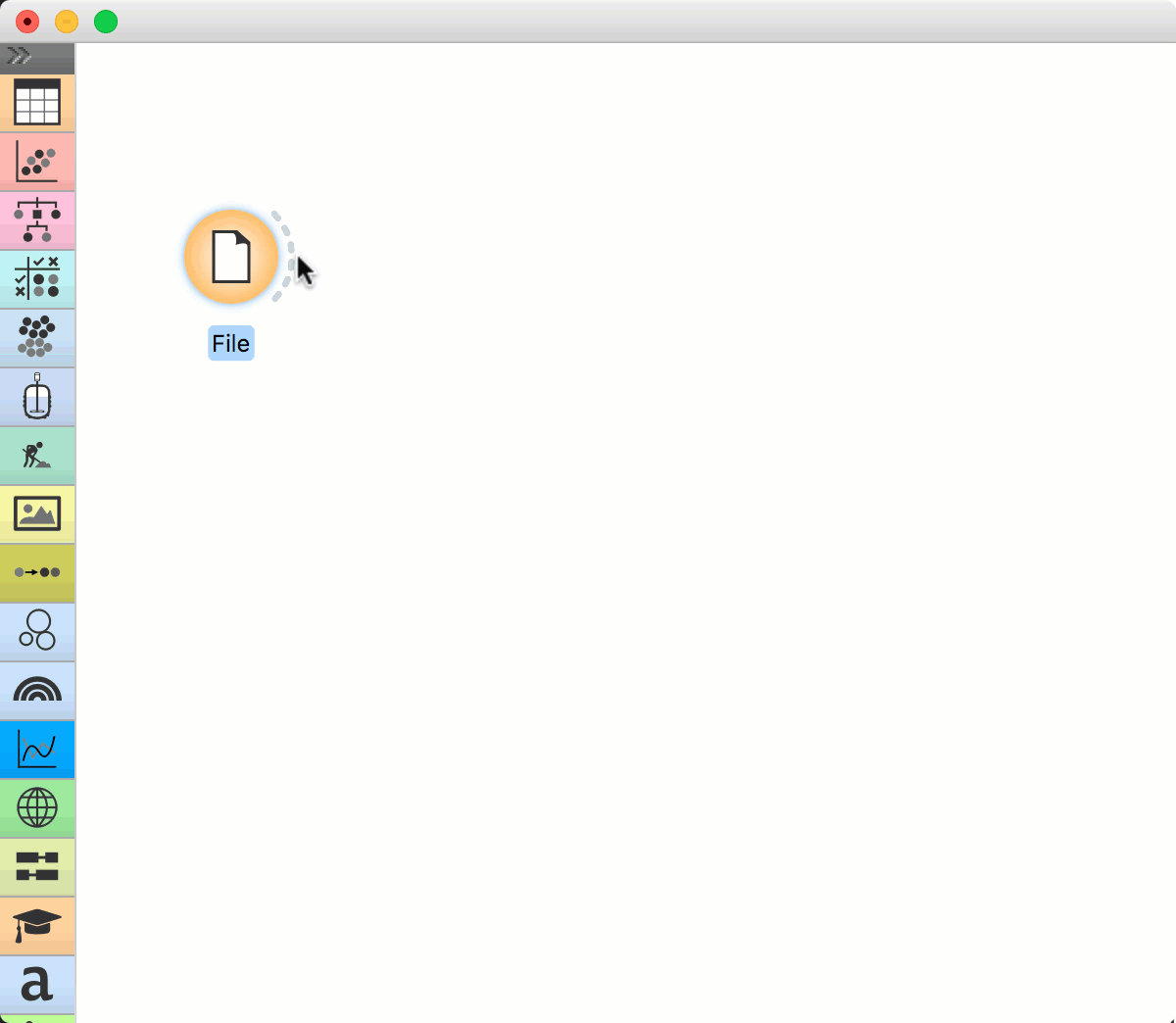
Let us start with a simple workflow. We will load the data with the File widget, say the famous Iris data set. Right-click on the canvas. A menu will appear. Start typing “File”, then press Enter to confirm the selection. File widget will be placed on the canvas.
File widget has an “ear” on its right side – this is the output of the widget. Click on the “ear” and drag a connection out of it. Upon releasing the connection, a menu will appear. Start typing the name of the widget to connect with the File widget, say Data Table. Select the widget and press enter. The widget is added to the canvas.
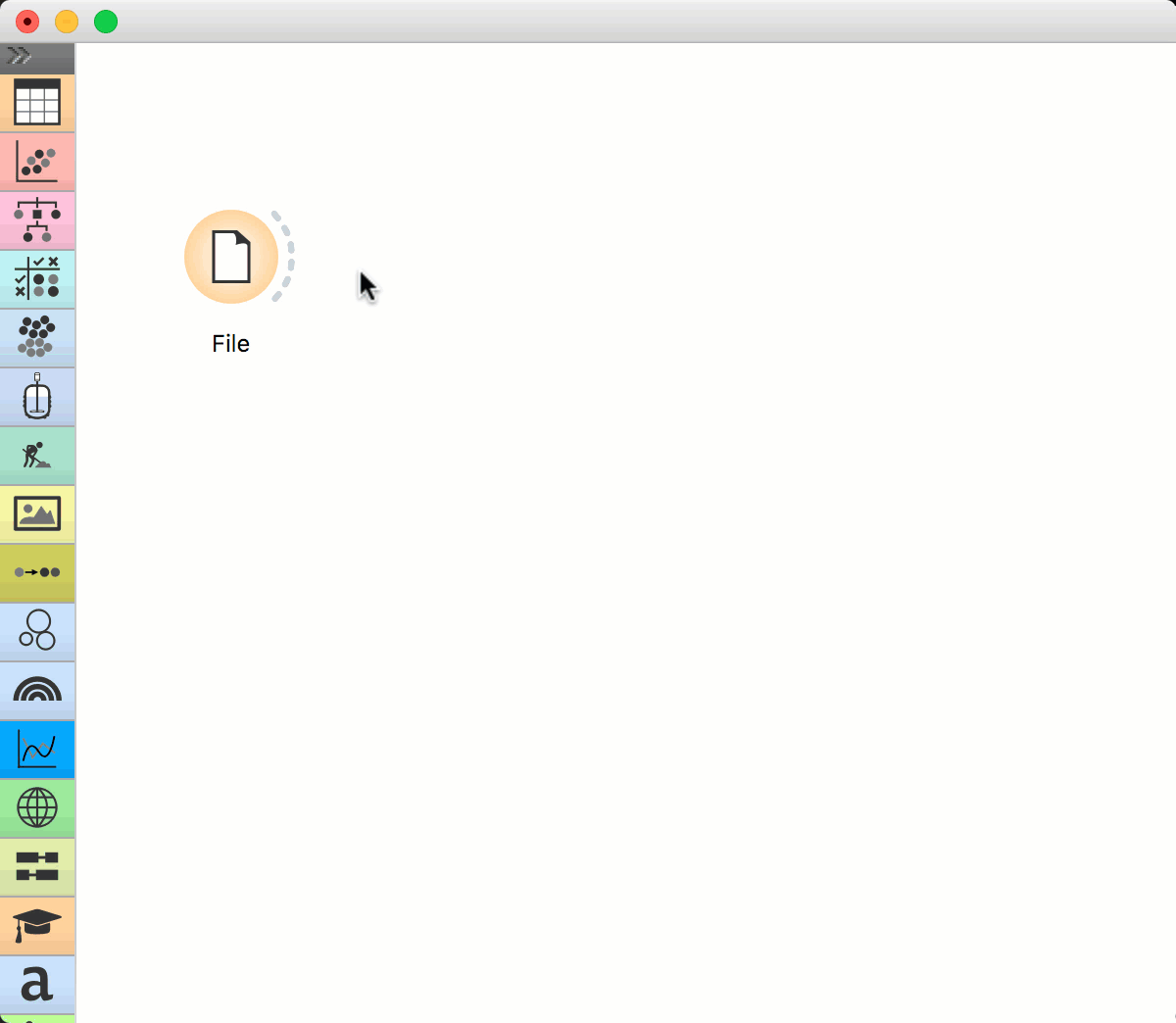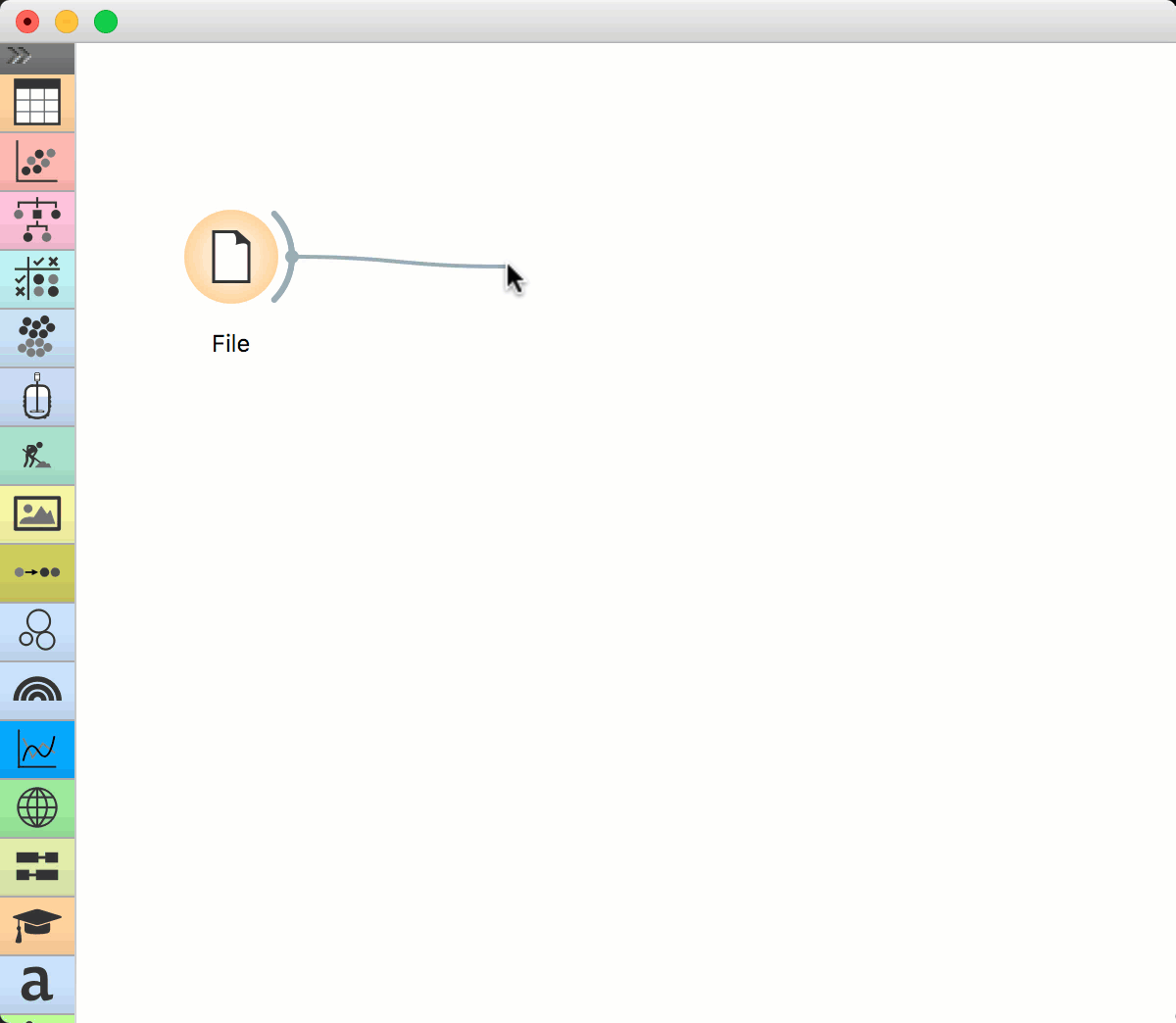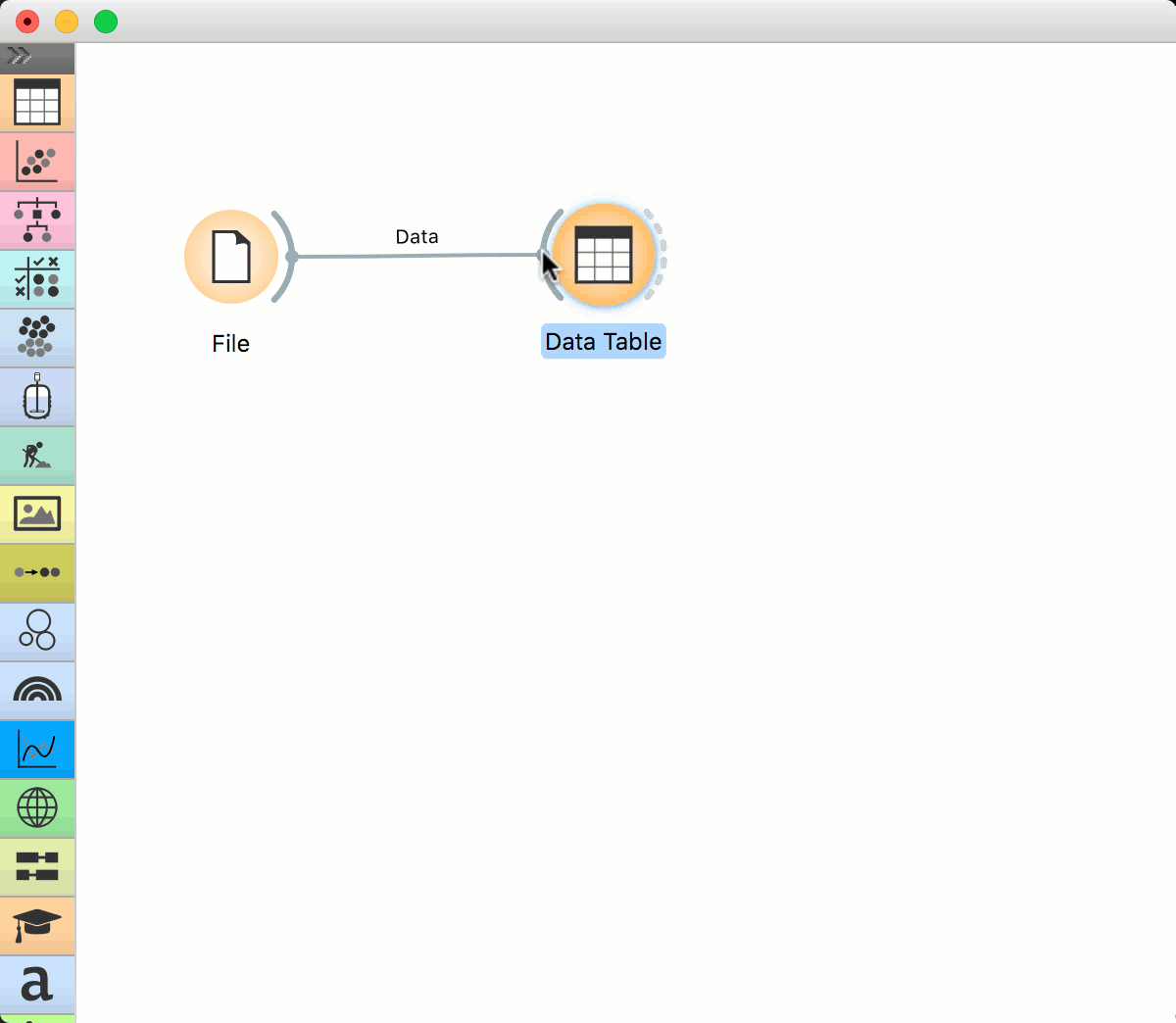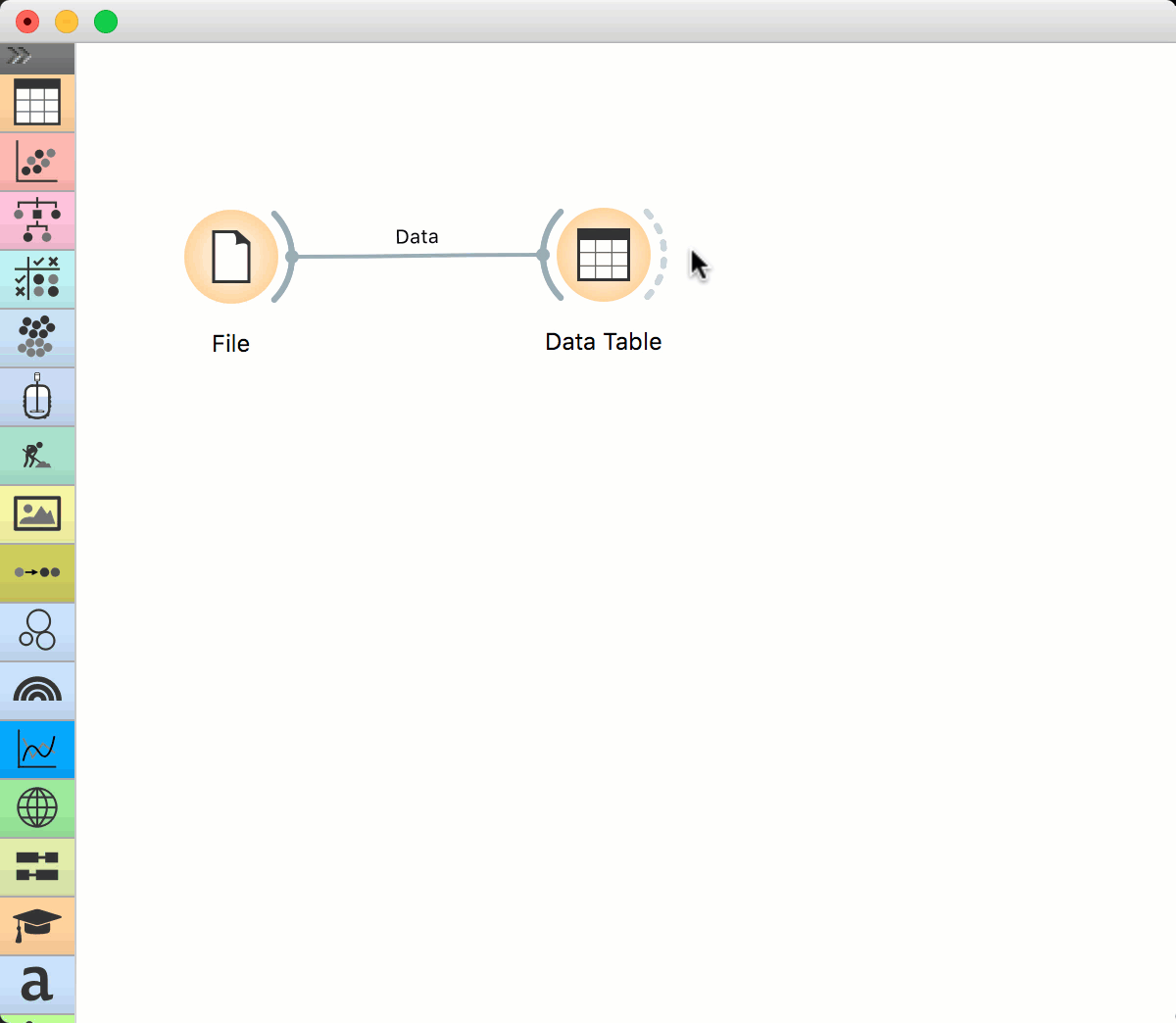
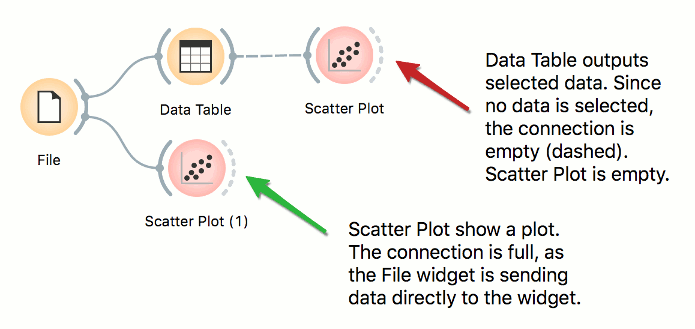
This is a simple workflow. The File widget loads the data and sends it to the output. Data Table receives the data and displays it in a table. Please note that Data Table is a viewer and passes onwards only the selection. The data is always available at the source – in the File widget.
Workflows with subsets
Visualizations in Orange are interactive, which means the user can select data instances from the plot and pass them downstream. Let us look at two examples with subsets.
Selecting subsets
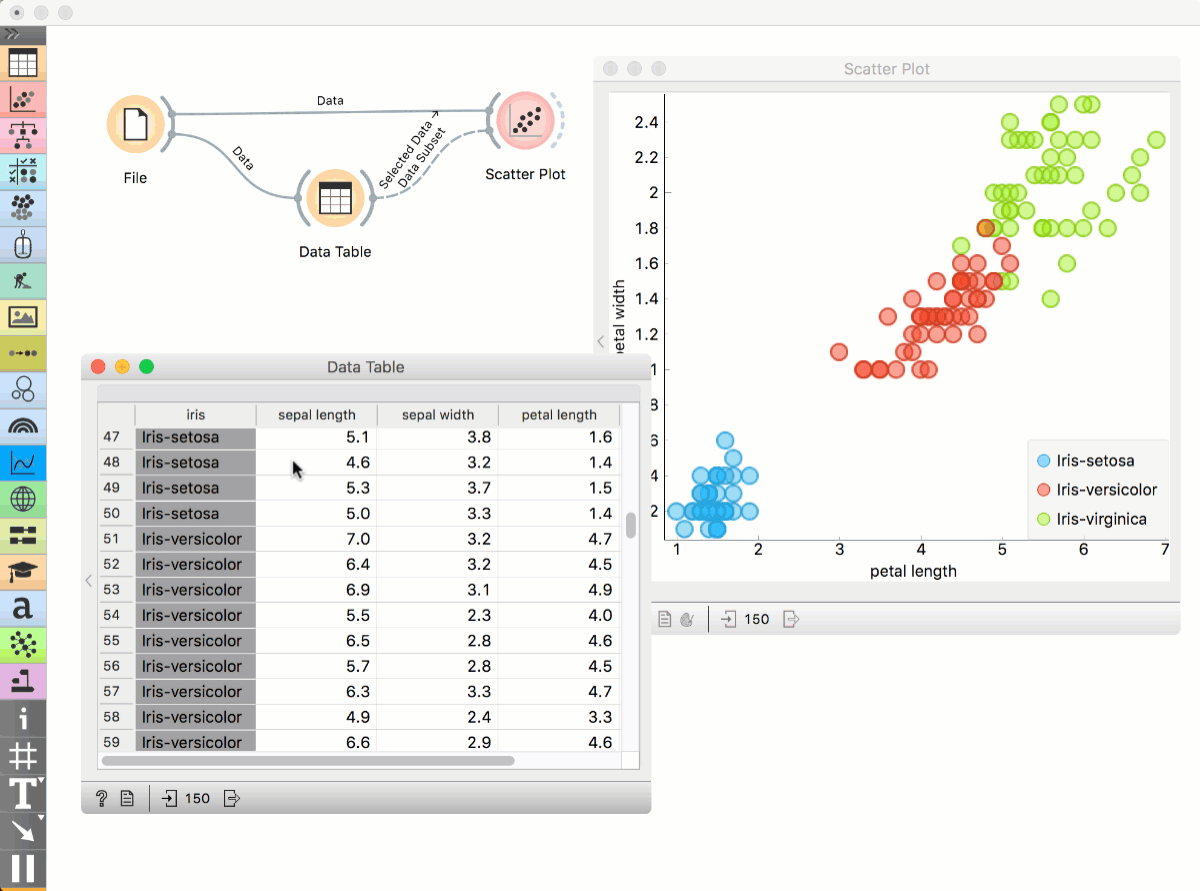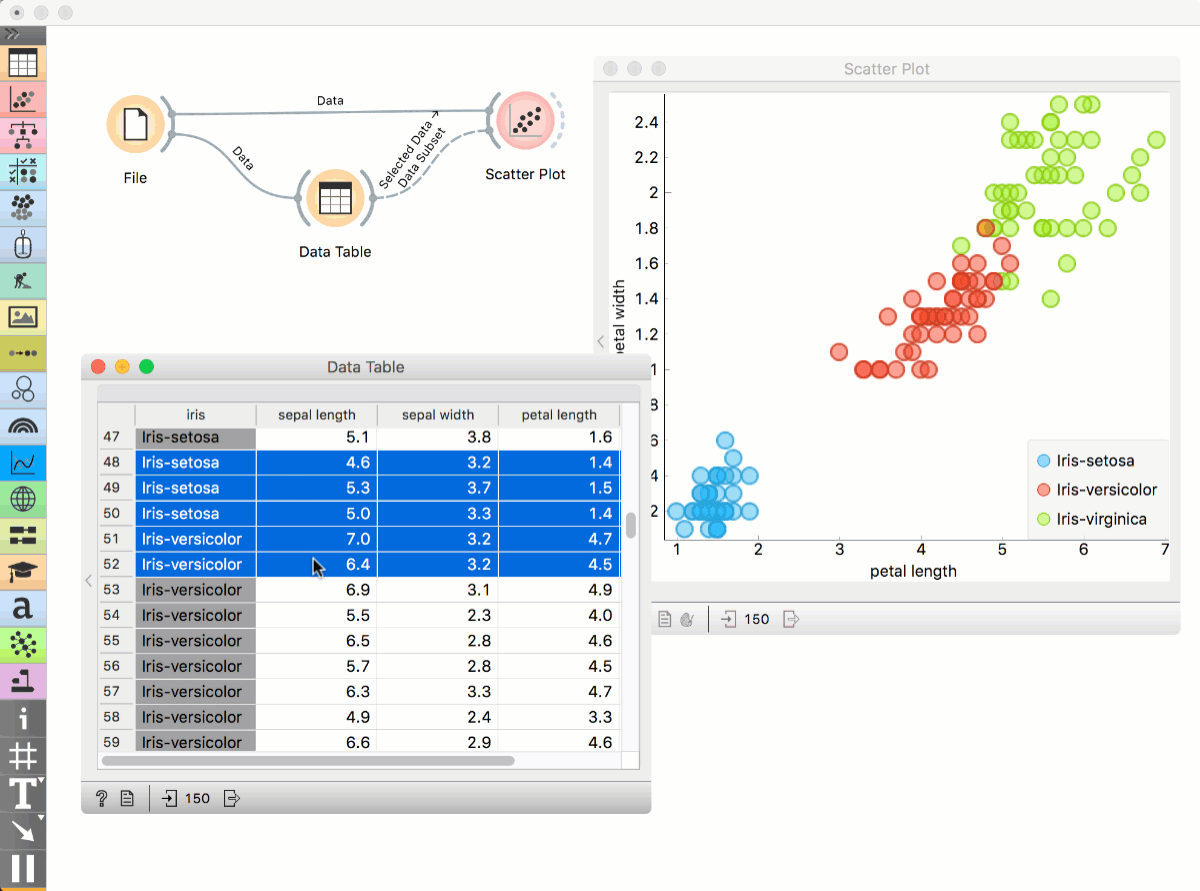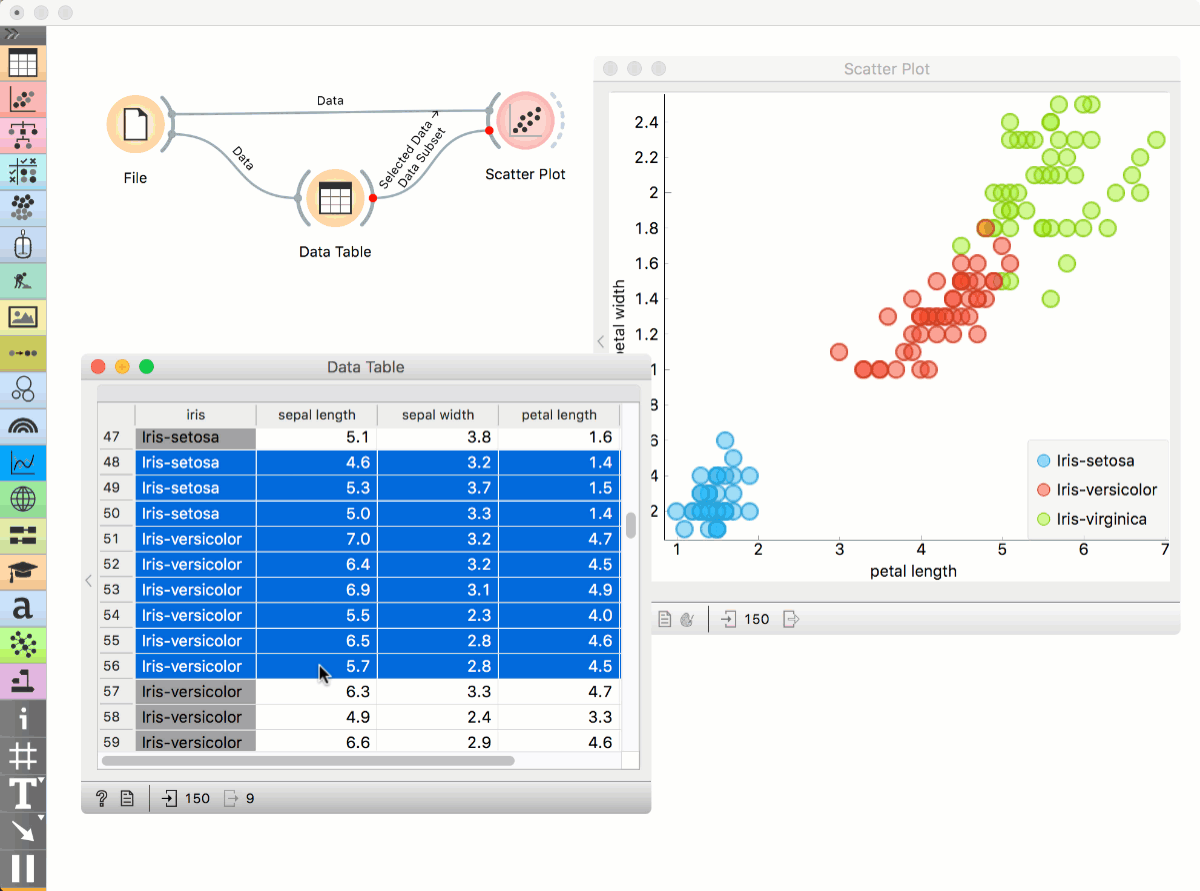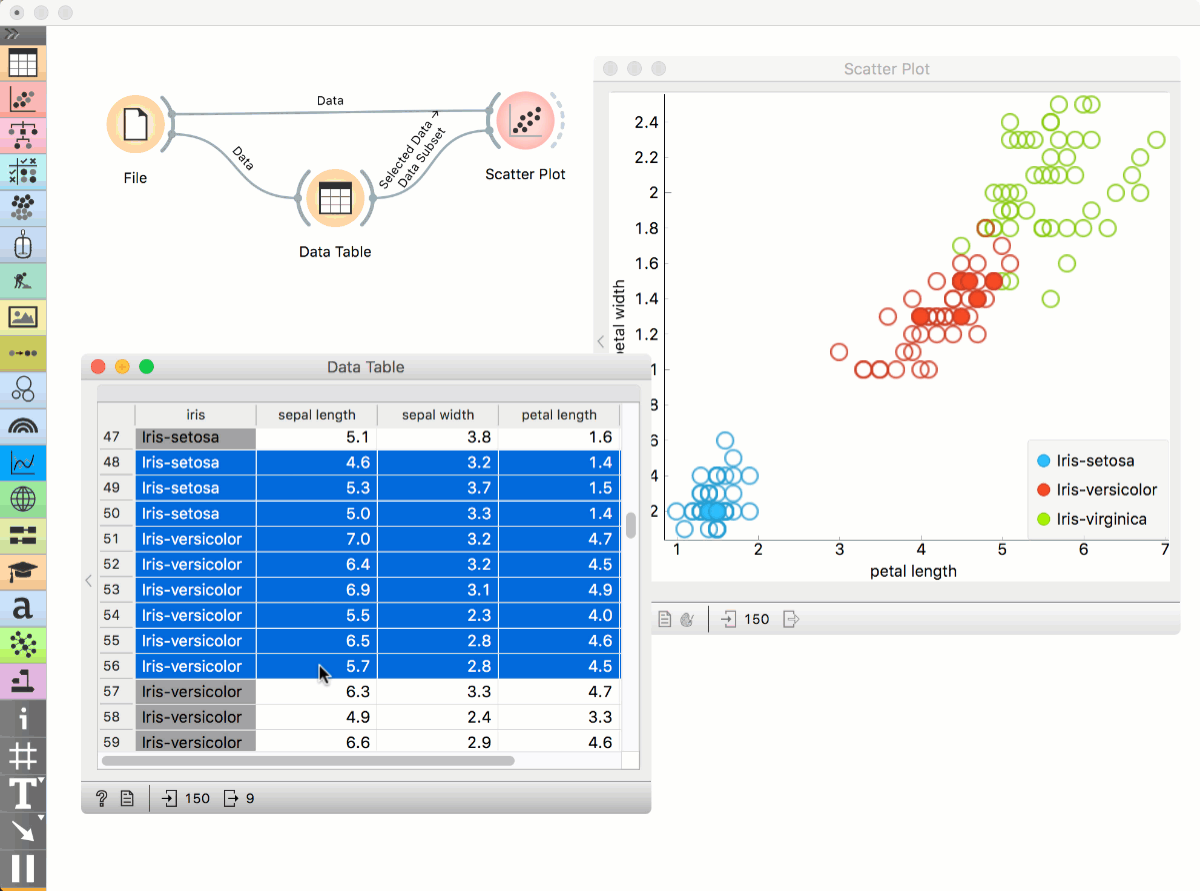
Place File widget on the canvas. Then connect Scatter Plot to it. Click and drag a rectangle around a subset of points. Connect Data Table to Scatter Plot. Data Table will show selected points.
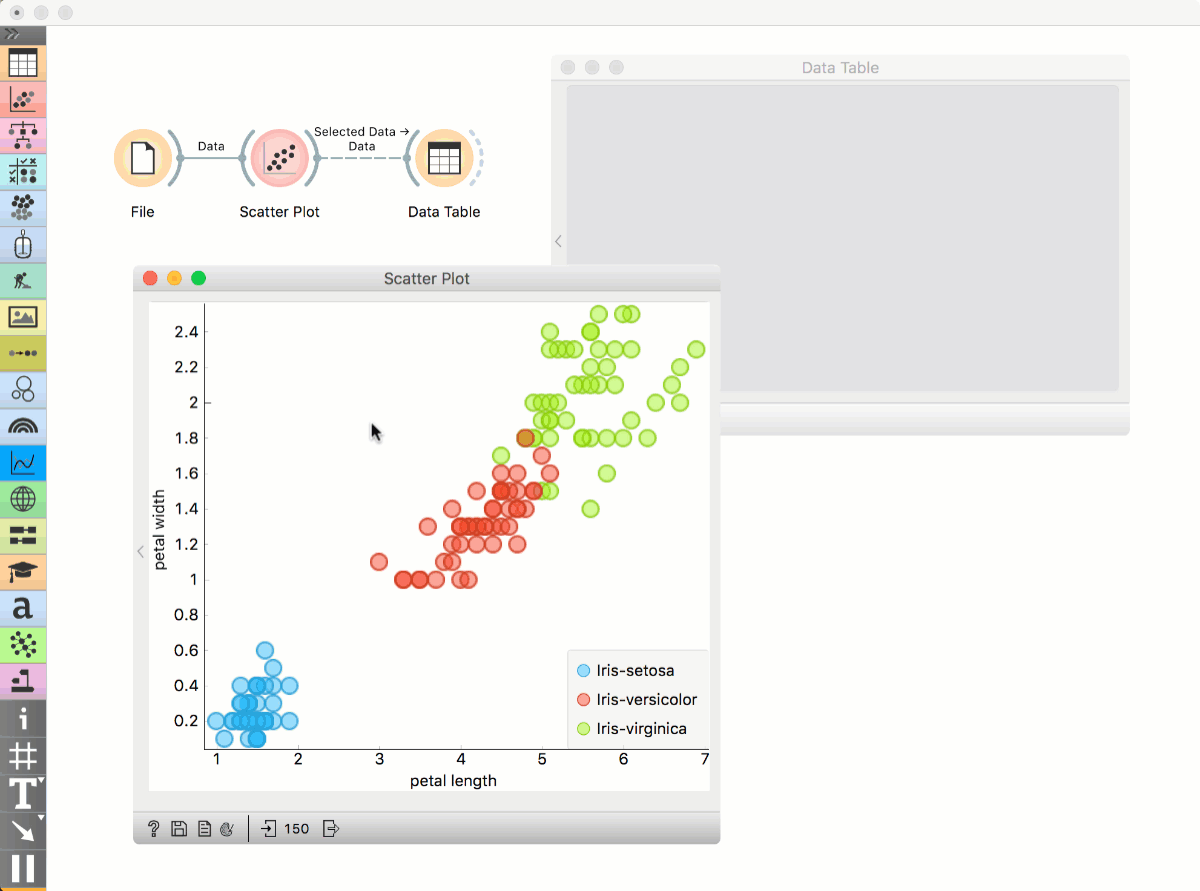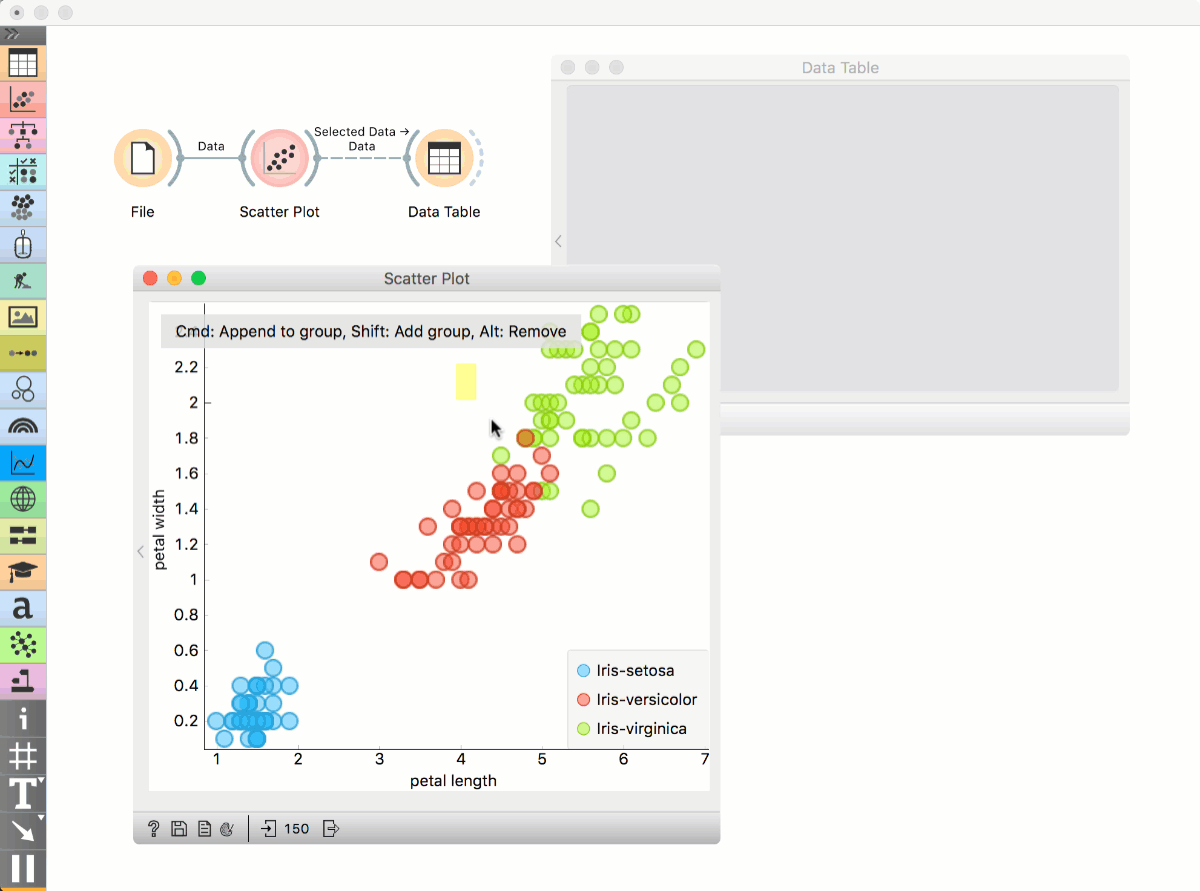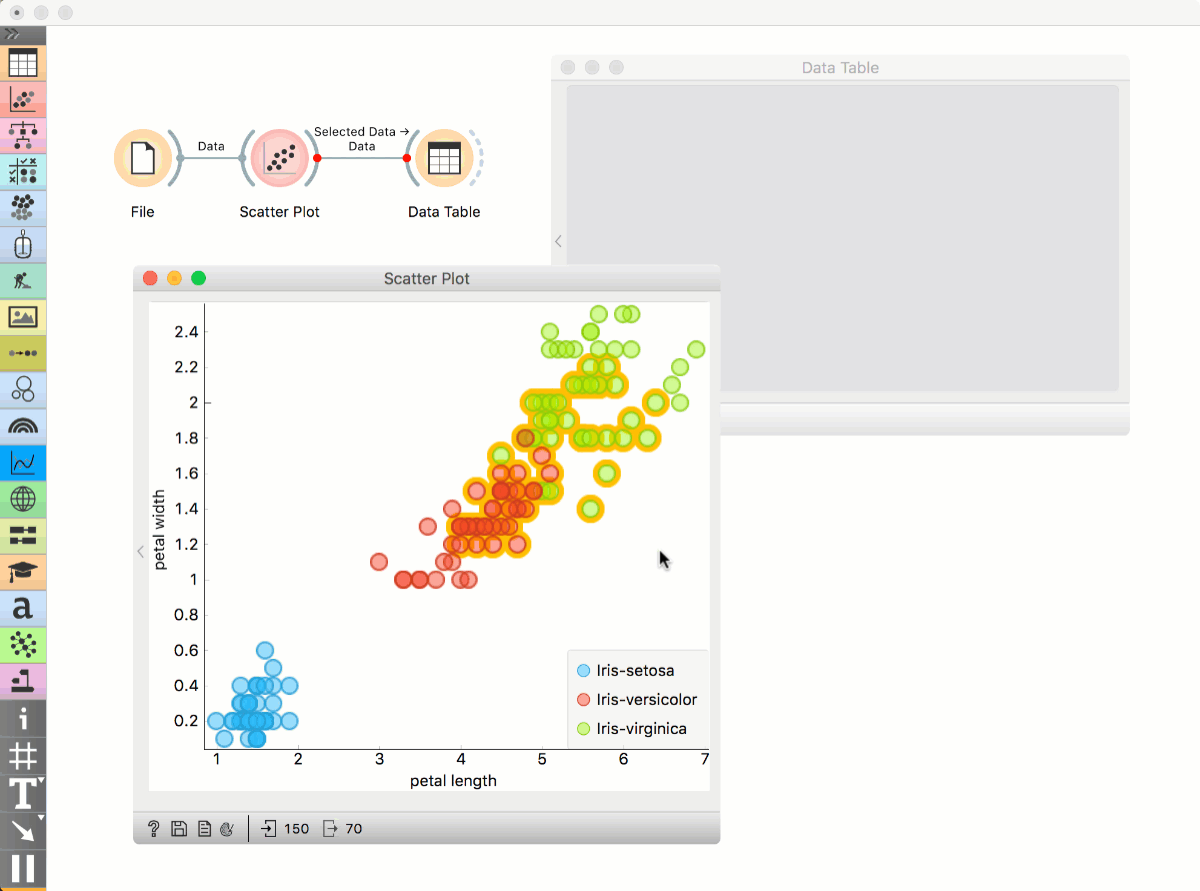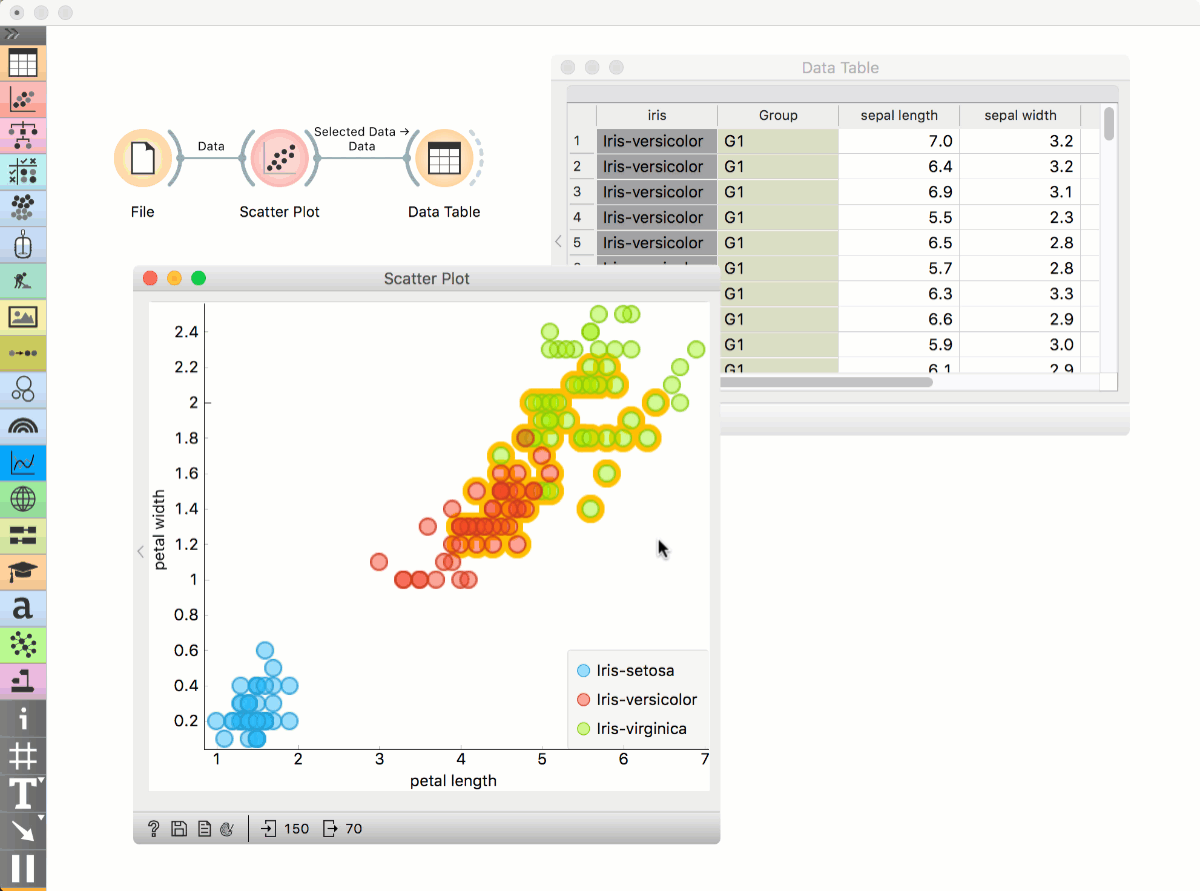
Highlighting workflows
Place File widget on the canvas. Then connect Scatter Plot to it and a Data Table. Connect Data Table to Scatter Plot. Select a subset of points from the Data Table. Scatter Plot will highlight selected points.
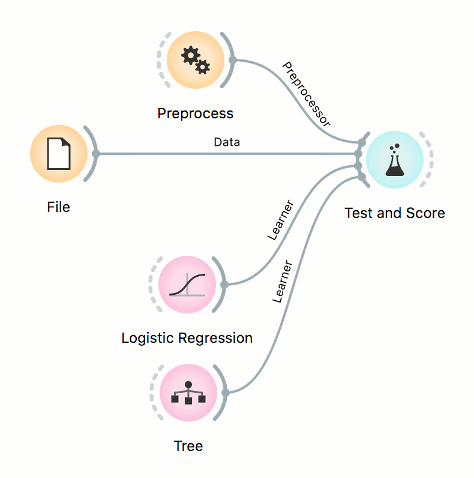
Workflows with models
Predictive models are evaluated in Test and Score widget, while predictions on new data are done in Predictions. Test and Score accepts several inputs: data (data set for evaluating models), learners (algorithms to use for training the model), and an optional preprocessor (for normalization or feature selection).
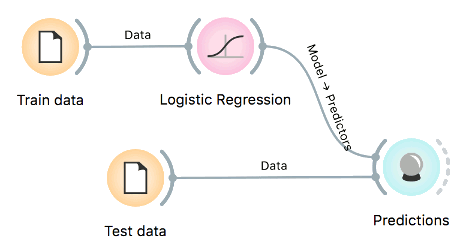
For prediction, the training data is first passed to the model. Once the model is trained, it is passed to Predictions. The Predictions widget also needs data to predict on, which are passed as a second input.
Improve your command line development experience with this book
Orange Visual Programming
Navigation
- Loading your Data
- Building Workflows
- Exporting Models
- Exporting Visualizations
- Learners as Scorers
- Report
- File
- CSV File Import
- Datasets
- SQL Table
- Save Data
- Data Info
- Aggregate Columns
- Data Table
- Select Columns
- Select Rows
- Data Sampler
- Transpose
- Discretize
- Continuize
- Create Instance
- Create Class
- Randomize
- Concatenate
- Select by Data Index
- Paint Data
- Pivot Table
- Python Script
- Formula
- Edit Domain
- Impute
- Merge Data
- Outliers
- Preprocess
- Apply Domain
- Purge Domain
- Rank
- Correlations
- Color
- Feature Statistics
- Melt
- Neighbors
- Unique
- Group by
- Box Plot
- Violin Plot
- Distributions
- Heat Map
- Scatter Plot
- Line Plot
- Bar Plot
- Venn Diagram
- Linear Projection
- Sieve Diagram
- Pythagorean Tree
- Pythagorean Forest
- CN2 Rule Viewer
- Mosaic Display
- Silhouette Plot
- Tree Viewer
- Nomogram
- FreeViz
- Radviz
- Constant
- CN2 Rule Induction
- Calibrated Learner
- kNN
- Tree
- Random Forest
- Gradient Boosting
- SVM
- Linear Regression
- Logistic Regression
- Naive Bayes
- AdaBoost
- Curve Fit
- Neural Network
- Stochastic Gradient Descent
- Stacking
- Load Model
- Save Model
- PCA
- Correspondence Analysis
- Distance Map
- Distances
- Distance Matrix
- Distance Transformation
- Distance File
- Save Distance Matrix
- Hierarchical Clustering
- k-Means
- Louvain Clustering
- DBSCAN
- MDS
- Example
- References
- t-SNE
- Manifold Learning
- Self-Organizing Map
Quick search
©2015, Orange Data Mining. | Powered by Sphinx 7.2.6 & Alabaster 0.7.13 | Page source
v: latest
Rank – Classificação
Classificação de atributos em conjuntos de dados de classificação ou regressão.
Entradas
- Dados: conjunto de dados de entrada
- Pontuador: modelos para pontuação de recursos
Resultados
- Dados reduzidos: conjunto de dados com atributos selecionados
- Pontuações: tabela de dados com pontuações de recursos
- Características: lista de atributos
O widget Classificação pontua variáveis de acordo com sua correlação com a variável de destino discreta ou numérica, com base em pontuadores internos aplicáveis (como ganho de informação, qui-quadrado e regressão linear) e quaisquer modelos externos conectados que suportem pontuação, como regressão linear, regressão logística, floresta aleatória, SGD, etc. O widget também pode lidar com dados não supervisionados, mas apenas por pontuadores externos, como PCA.
- Selecione métodos de pontuação. Veja as opções de classificação, regressão e dados não supervisionados na seção Métodos de pontuação .
- Selecione atributos para saída. None não produzirá nenhum atributo, enquanto All produzirá todos eles. Com seleção manual, selecione os atributos da tabela à direita. A melhor classificação produzirá n atributos mais bem classificados. Se Enviar Automaticamente estiver marcado, o widget comunica automaticamente as alterações para outros widgets.
- Barra de status. Produza um relatório clicando no ícone do arquivo. Observe a entrada e a saída do widget. À direita, são mostrados avisos e erros.
Métodos de pontuação (classificação)
- Ganho de informação: a quantidade esperada de informação (redução da entropia)
- Proporção de ganho : uma proporção entre o ganho de informação e a informação intrínseca do atributo, que reduz a tendência para características multivaloradas que ocorre no ganho de informação
- Gini : a desigualdade entre valores de uma distribuição de frequência
- ANOVA : a diferença entre os valores médios do recurso em diferentes classes
- Chi2 : dependência entre o recurso e a classe medida pela estatística qui-quadrado
- ReliefF : a capacidade de um atributo de distinguir entre classes em instâncias de dados semelhantes
- FCBF (Fast Correlation Based Filter) : medida baseada em entropia, que também identifica redundância devido a correlações de pares entre recursos
Além disso, você pode conectar determinados alunos que permitem pontuar os recursos de acordo com a importância deles nos modelos que os alunos constroem (por exemplo, Regressão Logística , Floresta Aleatória , SGD ). Observe que os dados são normalizados antes da classificação.
Métodos de pontuação (regressão)
- Regressão Univariada : regressão linear para uma única variável
- RReliefF : distância relativa entre os valores previstos (classe) das duas instâncias.
Além disso, você pode conectar alunos de regressão (por exemplo, Regressão Linear , Floresta Aleatória , SGD ). Observe que os dados são normalizados antes da classificação.
Método de pontuação (não supervisionado)
Atualmente, apenas o PCA é compatível com dados não supervisionados. Conecte o PCA ao Rank para obter as pontuações. As pontuações correspondem à correlação de uma variável com o componente principal individual.
Pontuação com os alunos
A classificação também pode usar determinados alunos para pontuação de recursos. Veja os alunos como marcadores, por exemplo.
Exemplo: Classificação e Seleção de Atributos
Abaixo, usamos o widget Rank imediatamente após o widget Arquivo para reduzir o conjunto de atributos de dados e incluir apenas os mais informativos:
Observe como o widget gera um conjunto de dados que inclui apenas os atributos com melhor pontuação:
Exemplo: Seleção de subconjunto de recursos para aprendizado de máquina
O que se segue é um exemplo um pouco mais complicado. No fluxo de trabalho abaixo, primeiro dividimos os dados em um conjunto de treinamento e um conjunto de teste. No ramo superior, os dados de treinamento passam pelo widget Rank para selecionar os atributos mais informativos, enquanto no ramo inferior não há seleção de recursos. Os conjuntos de dados originais e de recursos selecionados são passados para seus próprios widgets de teste e pontuação , que desenvolvem um classificador Naive Bayes e o pontuam em um conjunto de testes.
Para conjuntos de dados com muitos recursos, uma seleção ingênua de recursos do classificador bayesiano, como mostrado acima, geralmente produziria uma melhor precisão preditiva.
Programação Visual Laranja
Navegação
- Carregando seus dados
- Construindo Fluxos de Trabalho
- Exportando Modelos
- Exportando visualizações
- Alunos como artilheiros
- Relatório
- Arquivo
- Importação de arquivo CSV
- Conjuntos de dados
- Tabela SQL
- Guardar dados
- Informações de dados
- Colunas agregadas
- Tabela de dados
- Selecione Colunas
- Selecione linhas
- Amostrador de dados
- Transpor
- Discretizar
- Continuar
- Criar instância
- Criar aula
- Aleatória
- Concatenar
- Selecione por índice de dados
- Dados de pintura
- Tabela dinâmica
- Script Python
- Fórmula
- Editar domínio
- Imputar
- Mesclar dados
- Valores discrepantes
- Pré-processar
- Aplicar domínio
- Limpar domínio
- Classificação
- Correlações
- Cor
- Estatísticas de recursos
- Derretido
- Vizinhos
- Exclusivo
- Agrupar por
- Gráfico de caixa
- Enredo de violino
- Distribuições
- Mapa de calor
- Gráfico de dispersão
- Gráfico de linha
- Gráfico de barras
- Diagrama de Venn
- Projeção Linear
- Diagrama de peneira
- Árvore Pitagórica
- Floresta Pitagórica
- Visualizador de regras CN2
- Exibição em mosaico
- Gráfico de silhueta
- Visualizador de árvore
- Nomograma
- FreeViz
- Radviz
- Constante
- Indução de Regra CN2
- Aluno Calibrado
- kNN
- Árvore
- Floresta Aleatória
- Aumento de gradiente
- SVM
- Regressão linear
- Regressão Logística
- Baías ingénuas
- AdaBoost
- Ajuste de curva
- Rede neural
- Descida Gradiente Estocástica
- Empilhamento
- Modelo de carga
- Salvar modelo
- Gráfico de calibração
- Matriz de confusão
- Curva de desempenho
- Previsões
- Análise ROC
- Teste e pontuação
- PCA
- Análise de correspondência
- Mapa de distância
- Distâncias
- Matriz de Distância
- Transformação de Distância
- Arquivo de distância
- Salvar matriz de distância
- Agrupamento hierárquico
- k-médias
- Agrupamento de Louvain
- DBSCAN
- MDS
- Exemplo
- Referências
- t-SNE
- Aprendizagem múltipla
- Mapa Auto-Organizável
Pesquisa rápida
©2015, Mineração de Dados Orange. | Desenvolvido por
v: mais recente